
%in% で NA の判定ができるようなので、そのメモです。
確認するテストデータの作成
iris の偶数行の Sepal.Length が NA なデータを作成
library(dplyr)
i <- seq_len(trunc(nrow(iris) / 2)) * 2
df <- iris
df[i, "Sepal.Length"] <- NA偶数の Speal.Length が NA になってます。
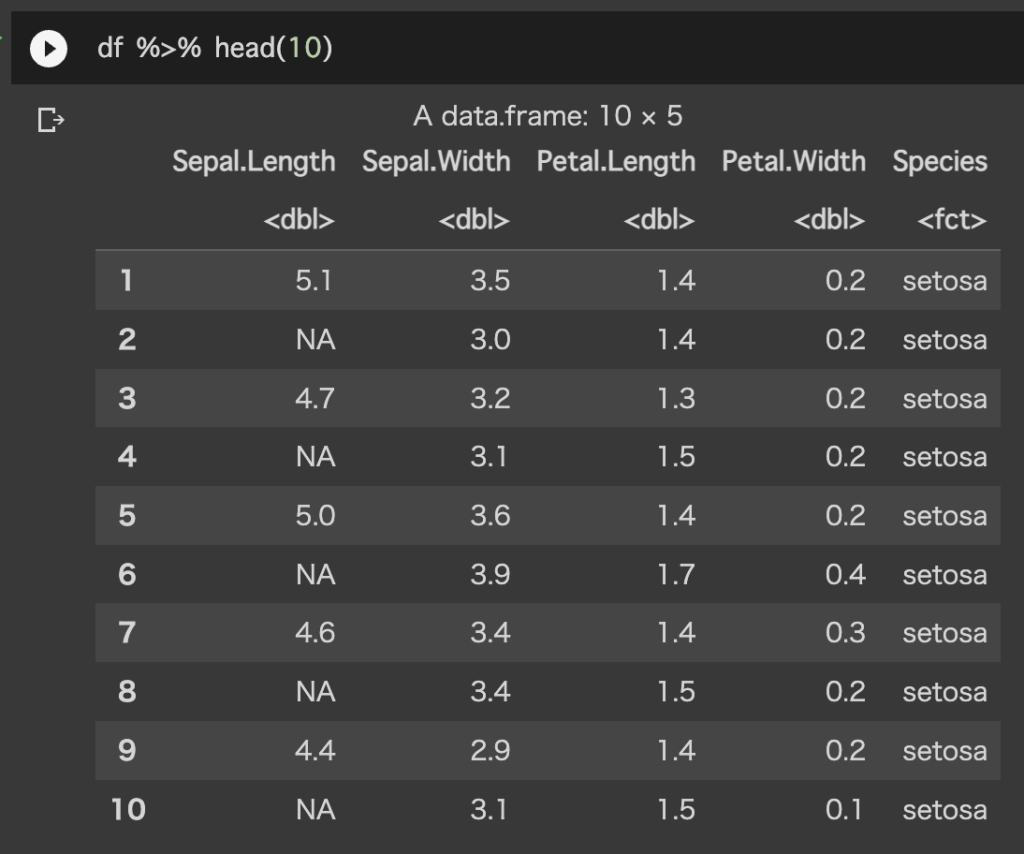
%in% で Speal.Length が NA の行を得る
df %>% filter(Sepal.Length %in% NA) %>% head(10)NA の行が得られました。
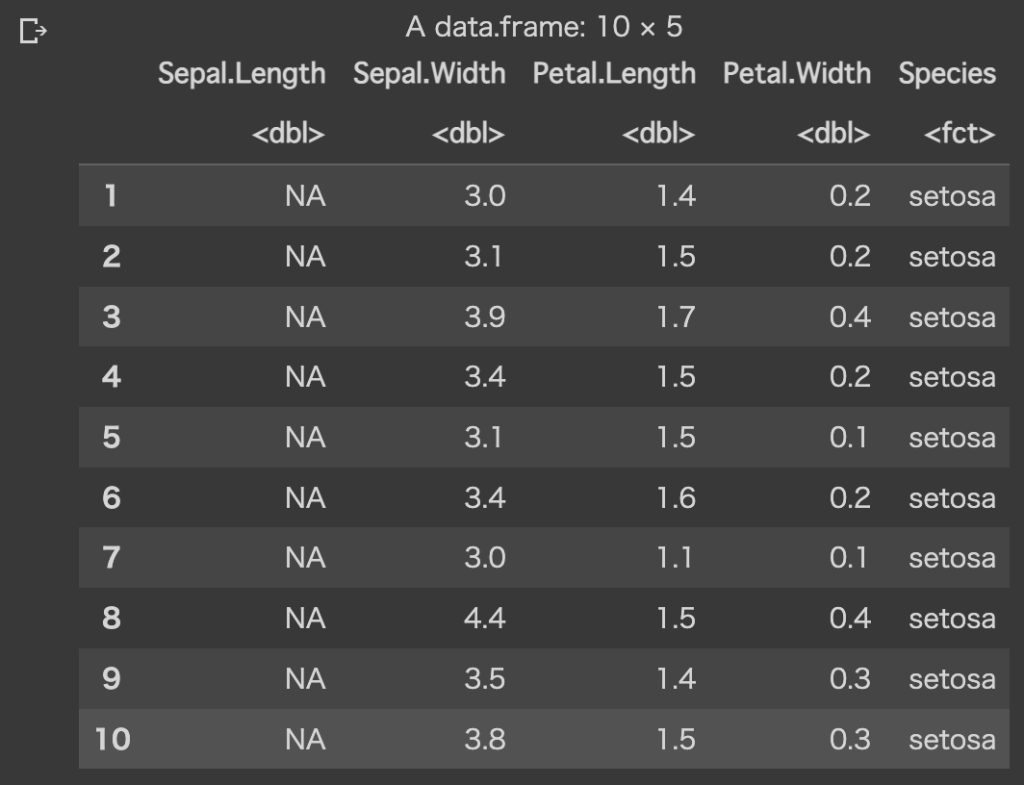
is.na() 使えば?
単に NA だけ判定したいならその通りで、
df %>% filter(is.na(Sepal.Length)) %>% head(10)の方が分かりやすいです。
%in% にしたのは、変数と比較してフィルターしたい場合に融通が効きそうだったからです。
例えば、
target_value <- 5.1
df %>% filter(Sepal.Length %in% target_value) %>% head(10)として、得たい行の条件が target_value 次第だったとき、
target_value <- NAだった場合も、同じ filter で対応できるなと。
以上、そんなお話でした。


コメント